Índice Gini + Curva de Lorenz en Python con datos de INEGI y CEPAL
El Índice Gini es un indicador económico que calcula la desigualdad de ingresos entre la población de un país o región, el cual se encuentra entre 0 y 1, siendo cero la máxima igualdad (todos los ciudadanos tienen la misma cantidad de ingresos). Este concepto de desigualdad se puede mostrar gráficamente a través de la curva de Lorenz
La curva de Lorenz es una representación gráfica de la desigualdad en la distribución del ingreso o producto existente en un país. En el eje X se situan los acumulados de población, normalmente deciles y en el eje Y los acumulados de renta expresados en porcentaje.
Aquí tenemos la curva de Lorenz de Brasil, México y Uruguay para el año 2018:
En esta oportunidad desarrollaremos con Python un algoritmo que nos permita calcular este índice junto con su versión gráfica abordando dos bases de datos a través de sus APIs: la de INEGI (para México) y la de CEPAL (para países latinoamericanos).
Esta publicación se dividirá en las siguientes partes. Primero, plantearemos el método matemático a utilizar y aseguraremos la conexión, descarga y homologación de datos desde las APIs de Inegi (para México) y de CEPALSTAT (para América Latina):
- Planteamiento matemático
- Conexión e integración con API de INEGI
- Conexión e integración con API de CEPALSTAT
Después, crearemos las funciones necesarias para el cálculo del índice, junto con su versión gráfica (curva de Lorenz), usando ambas fuentes de datos:
- Función de cálculos sobre DataFrame
- Función de graficación
- Tips para publicación
Antes de comenzar, quiero aclarar brevemente el por qué usar la API de INEGI si con CEPALSTAT bastaría. Mi propósito es acercar a los economistas mexicanos a Python. Durante mi paso por la Universidad, tuve una formación como economista de parte de académicos muy talentosos, pero noté una área descuidada: todos los métodos estadísticos, numéricos, de graficación y relacionados se llevan a cabo con Excel, o en el mejor de los casos con Stata. Como alguien aficionado a la programación, me propuse llevar esos métodos que en muchos casos se quedan cortos al terreno de Python para poder hacer ciencia económica de una forma más programática, profesional y con resultados atractivos y de calidad de cara al público.
Dicho esto, la vida me ha dado una oportunidad que no quiero desaprovechar: colaborar con mi Universidad en este tema. Entonces, en ese tenor, el propósito de esta y otras publicaciones dentro de este blog personal tendrá la función de realizar esta colaboración, sirviendo como libreta abierta de apuntes para el propósito inicial: acercar Python a los economistas mexicanos.
INEGI, junto con Banxico, son dos bases de datos cruciales para los economistas mexicanos, es por eso que le estoy dando este mimo y trato especial a la integración con bases mexicanas, pero sin caer en el error de “mirarme el ombligo” al sólo considerar mi país. También se incluye integración con CEPALSTAT para considerar a la comunidad latinoamericana, que le da un enfoque más regional a esta publicación.
Requerimientos
- requests – Gestión de peticiones HTTP (necesarias para conexión y descarga de datos con APIs)
- numpy – Python Matemático
- pandas – Análisis y manipulación de datos
- inegipy: Módulo de Python para obtener datos de la API de Inegi (BIE, BISE, DENUE) a DataFrames de pandas. Desarrollado por Andrés Lomelí
- plotly – Gráficos estáticos e interactivos con calidad de publicación.
- chart-studio – Publicación de gráficos en sitios web.
- Jupyter Notebook: ya sea en Google Colab o en local.
Instalación de requerimientos
Podemos instalar los módulos necesarios con el comando pip. En terminal local:
(venv) pip install requests numpy pandas inegipy plotly chart-studioSi estamos en Google Colab, para ejecutar un comando en terminal en una celda de código se hace de la siguiente manera:
!pip install requests numpy pandas inegipy plotly chart-studioPlanteamiento matemático
![\[ (1)Gini = 1 - \sum_{i=1}^{n} (X_{i-1} - X_i)(Y_i + Y_{i+1}) \]](https://dlimon.net/wp-content/ql-cache/quicklatex.com-ca57365aa9f25c23cb5da17ebe54578f_l3.png "Rendered by QuickLaTeX.com")
Donde:
 : Acumulado porcentual de población
: Acumulado porcentual de población Acumulado de ingreso
Acumulado de ingreso
Lo primero a hacer es importar todo lo necesario para esta publicación:
# Necesarios
import json
import requests
from INEGIpy import Indicadores
import plotly.graph_objects as go
# Opcional para publicación
import chart_studio
import chart_studio.plotly as py
import plotly.tools as tlsDespues, queremos obtener los datos de población e ingreso por deciles tanto de INEGI como de CEPAL. He definido una tabla con los indicadores y datos clave necesarios de cada API:
| Indicador | ID INEGI | ID CEPAL (INDICADOR 3390) |
| Decil 1 de ingreso | 6207048662 | 921 |
| Decil 2 de ingreso | 620704866 | 922 |
| Decil 3 de ingreso | 6207048669 | 923 |
| Decil 4 de ingreso | 6207048666 | 924 |
| Decil 5 de ingreso | 6207048663 | 925 |
| Decil 6 de ingreso | 6207048668 | 926 |
| Decil 7 de ingreso | 6207048670 | 927 |
| Decil 8 de ingreso | 6207048671 | 928 |
| Decil 9 de ingreso | 6207048667 | 929 |
| Decil 10 de ingreso | 6207048664 | 930 |
Entonces, la lista de indicadores quedaría así:
INDICADORES_GLOBAL: list[tuple] = [
# (indicador, id inegi, id cepal)
('Decil 1', 6207048662, 921),
('Decil 2', 6207048665, 922),
('Decil 3', 6207048669, 923),
('Decil 4', 6207048666, 924),
('Decil 5', 6207048663, 925),
('Decil 6', 6207048668, 926),
('Decil 7', 6207048670, 927),
('Decil 8', 6207048671, 928),
('Decil 9', 6207048667, 929),
('Decil 10', 6207048664, 930)]
Conexión e integración con API de INEGI
El módulo INEGIpy facilita el acceso a indicadores de la API de INEGI, entregando los datos en DataFrames de pandas. Lo primero que necesitamos es obtener un token de acceso a la API:
Usando este formulario podremos obtener un token de acceso enviado a nuestro correo electrónico.
Adicionalmente, estuve usando el Constructor de Consultas y con un poco de análisis obtuve el token usado por INEGI para el constructor:
96fbd1bf-21e6-28e3-6e64-2b15999d2c89Cabe mencionar que este token sólo debe ser usado para fines de desarrollo y testeo. Es recomandado usar un token propio para cosas más serias. Para el código de esta publicación usaremos el token público del constructor de consultas.
INEGI_TOKEN="96fbd1bf-21e6-28e3-6e64-2b15999d2c89"
inegi_api = Indicadores(INEGI_TOKEN)Con el mapeo cargado en INDICADORES_GLOBAL, podemos usar la función obtener_df de INEGIpy, la cual recibe los siguientes parámetros:
- indicadores: Lista de ids de los indicadores a consultar
- nombres: Lista de nombres de los indicadores
- banco: Fuente de datos a consultar (en este caso, BISE)
- metadatos: Inluír o no metadatos (True/False)
Entonces usamos un par de lists comprehensions para obtener los parámetros indicadores y nombres y llamamos a la función:
nombres: list[str] = [nombre for nombre, _, _ in INDICADORES_GLOBAL]
indicadores: list[int] = [indicador for _, indicador, _ in INDICADORES_GLOBAL]
decilesmx: 'DataFrame' = inegi_api.obtener_df(
indicadores=indicadores,
nombres=nombres,
banco='BISE',
metadatos=False)
print(decilesmx)Output:
>>>
Decil 1 Decil 2 Decil 3 Decil 4 \
fechas
2016-01-01 8166.342268 14206.057701 18918.083052 23555.608409
2018-01-01 9113.231866 16099.590912 21428.308607 26696.370131
2020-01-01 9937.777739 16862.471498 22273.713530 27558.387117
2022-01-01 13410.760364 22421.359574 29200.796563 35947.036512
Decil 5 Decil 6 Decil 7 Decil 8 \
fechas
2016-01-01 28812.499753 34836.645699 42431.241844 53383.457300
2018-01-01 32317.818967 38956.685714 47264.244337 58885.387456
2020-01-01 33366.628170 40107.593574 48670.215831 60597.788863
2022-01-01 43340.893747 51924.437563 62411.649150 76735.609921
Decil 9 Decil 10
fechas
2016-01-01 72040.747745 168855.355115
2018-01-01 78591.152122 166749.859911
2020-01-01 80436.753841 163281.516931
2022-01-01 100866.001980 200695.924202 El objeto decilesmx es un DataFrame de pandas, teniendo como columnas los deciles de ingreso y por filas los periodos; en este caso de 2016 a 2022 de forma bianual. Lo primero será decidir para qué año queremos el cálculo, por lo que podemos seleccionar los datos sólo del año de interés:
decilesmx2018 = decilesmx.loc["2018"].reset_index().drop(columns=["fechas"]).T
decilesmx2018["tasa_ingreso"] = (decilesmx2018[0]/decilesmx2018[0].sum())
decilesmx2018 = decilesmx2018[["tasa_ingreso"]]
print(decilesmx2018)Output:
>>>
tasa_ingreso
Decil 1 0.018370
Decil 2 0.032452
Decil 3 0.043193
Decil 4 0.053812
Decil 5 0.065143
Decil 6 0.078525
Decil 7 0.095271
Decil 8 0.118696
Decil 9 0.158417
Decil 10 0.336120Se aplicaron cuatro acciones:
- Filtrado de fechas, seleccionando sólo los registros de 2018
- reset_index() para resetear el nombre de las columnas por índices numéricos, ya que los datos serán transpuestos.
- drop() para eliminar la columna de fecha, ya que no es necesaria para el cálculo.
- T para transponer el objeto.
- Se renombra la columna 0 a tasa_ingreso
Finalmente, encapsulamos esta lógica en una función:
def deciles_inegi(token: str, año: int) -> 'DataFrame':
from INEGIpy import Indicadores
import pandas as pd
global INDICADORES_GLOBAL
inegi_api = Indicadores(token)
nombres: list[str] = [nombre for nombre, _, _ in INDICADORES_GLOBAL]
indicadores: list[int] = [indicador for _, indicador, _ in INDICADORES_GLOBAL]
deciles: 'DataFrame' = inegi_api.obtener_df(
indicadores=indicadores,
nombres=nombres,
banco='BISE',
metadatos=False)
deciles_año = deciles.loc[f"{año}"].reset_index().drop(columns=["fechas"]).T
deciles_año["tasa_ingreso"] = (deciles_año[0]/deciles_año[0].sum())
deciles_año = deciles_año[["tasa_ingreso"]]
return deciles_año
deciles_inegi = deciles_inegi(TOKEN, 2018)
print(deciles_inegi)>>>
tasa_ingreso
Decil 1 0.018370
Decil 2 0.032452
Decil 3 0.043193
Decil 4 0.053812
Decil 5 0.065143
Decil 6 0.078525
Decil 7 0.095271
Decil 8 0.118696
Decil 9 0.158417
Decil 10 0.336120Conexión e integración con API de CEPAL
Para obtener los deciles de ingreso de la API de CEPALSTAT hay que hacerlo de forma manual. Es por ello que instalamos el módulo requests.
Usando el explorador de datos de CEPALSTAT identifiqué el indicador y parámetros de mi interés. Para esta publicación obtendremos el índice Gini de 2018 para tres países: Brasil, México y Uruguay. A continuación detallo los detalles de la consulta.
Así luce el explorador de CEPALSTAT:
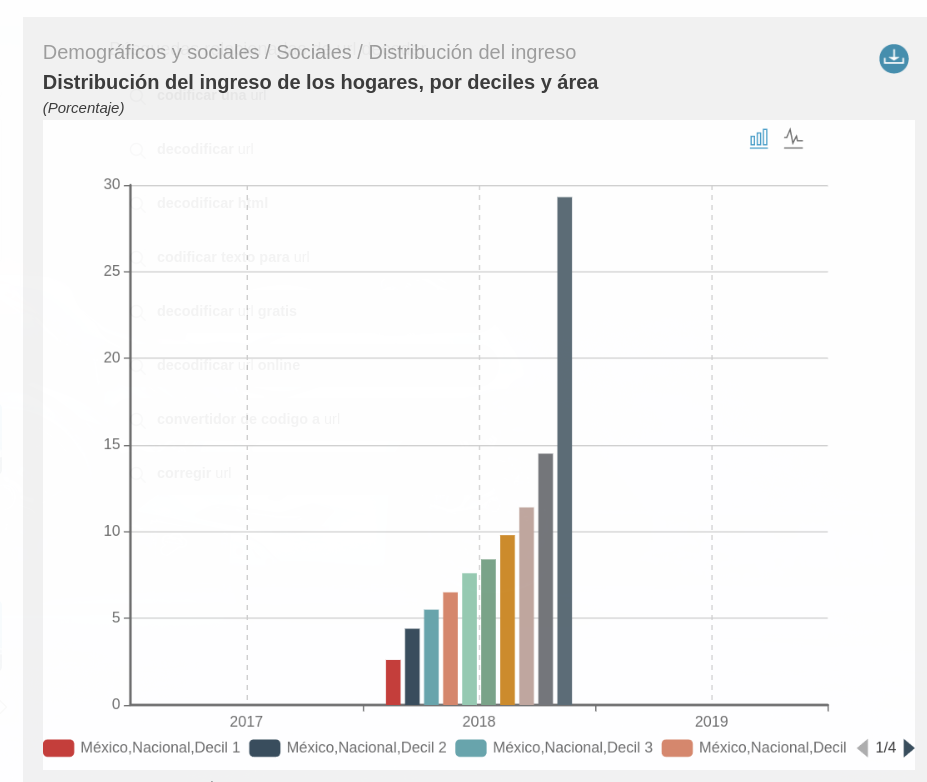
Endpoint a consultar
Usaremos el indicador Distribución del ingreso de los hogares, por deciles y área, con id 3390, junto con los parámetros almacenados en la lista INDICADORES_GLOBAL:
GET https://api-cepalstat.cepal.org/cepalstat/api/v1/indicator/3390/dataParámetros de consulta
El filtrado de datos se realiza a través de los parámetros de consulta. El más importante es members, ya que en él se definen todos los filtros a aplicar. Primero, veamos todos los parámetros, y luego profundizemos en members:
- members: Filtros de consulta. Son un conjunto de enteros (int) separados por coma
- lang: Lenguaje de respuesta (inglés y español disponibles)
- format: Formato de respuesta. Siempre se preferirá json y este es el caso
- in: Es un valor binario representado en tipo entero (int) donde 0 agrega todas las dimensiones (ids) disponibles o 1 agrega sólo las presentes en el dataset de la consulta. Se usa 1 para esta publicación
El parámetro members: crucial para el filtrado
El conjunto de enteros (int) del parámetro members representa los distintos filtros a aplicar al indicador. Estos son los parámetros que se consultan para este indicador:
- País: 222 (Brasil), 233 (México) y 258 (Uruguay)
- Área geográfica: 327 (Nacional). También se puede filtrar por 331 (Rural) o 330 (Urbana)
- Deciles: Para deciles de ingreso del 1 al 10 respectivamente: Invervalo cerrado [921,930]
Para consultar todo el catálogo de filtrado con el parámetro members para el indicador 3390, se puede consultar el siguiente endpoint (parámetros incluídos):
GET https://api-cepalstat.cepal.org/cepalstat/api/v1/indicator/3390/dimensions?lang=es&format=json&in=1Dicho esto, aquí hay un ejemplo de una consulta HTTP pura hecha con Postman para Brasil en 2018:
GET https://api-cepalstat.cepal.org/cepalstat/api/v1/indicator/3390/data?members=222,327,921,922,923,924,925,926,927,928,929,930,29188&lang=es&format=json&in=1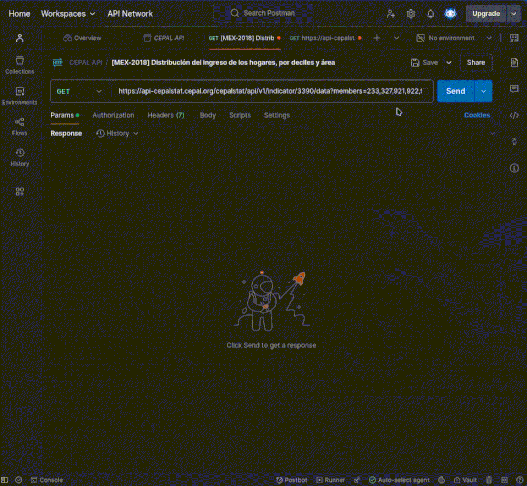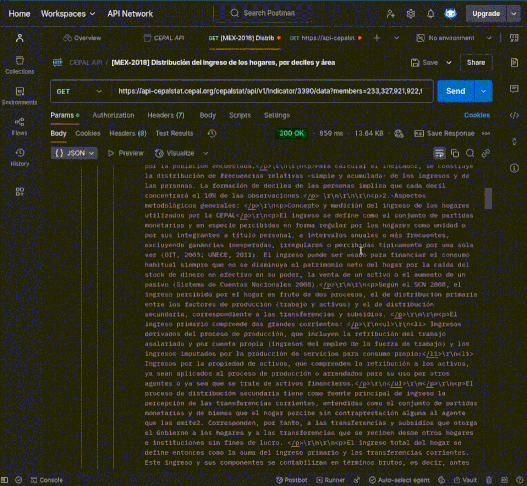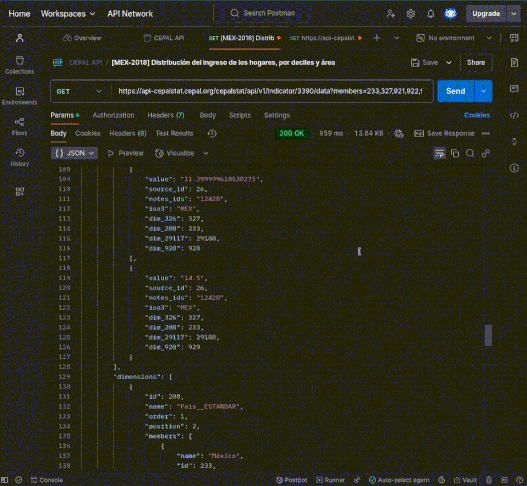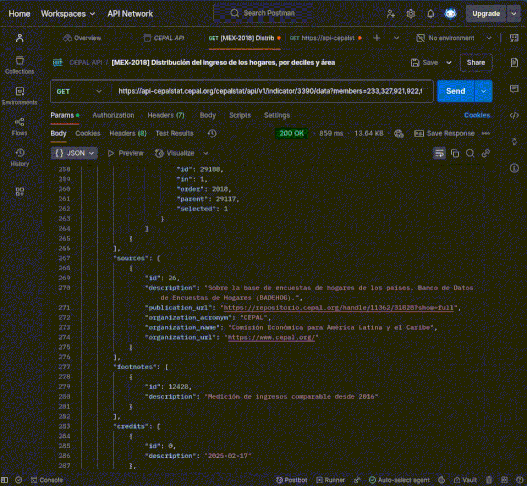
Como se puede observar, la petición GET devuelve un conjunto extenso de datos, lo cual es bueno, pero es importante saber filtar. Como esta publicación no es un tutorial de APIs y HTTP, he filtrado los Deciles de ingreso, que son los datos de interés, con el siguiente orden dentro de la anidación del payload JSON de respuesta:
payload->body->data[list]Es decir, los datos con los deciles de ingreso se encuentran dentro de body>data, conteniendo 10 elementos, los cuales tienen id del 921 al 930, que son del Decil 1 al Decil 10 respectivamente
Hasta este punto hemos estudiado el endpoint lo suficiente como para llevarlo a Python y obtener los datos necesarios para calcular el índice, entonces, definimos constantes con los filtros necesarios para obtener los deciles de ingreso para Argentina en 2018 y probamos el endpoint:
# Indicador deciles de ingreso
INDICADOR = 3390
PAISES = [222,233,258]
AREA_GEOGRAFICA = 327 # Nacional
AÑOS = 29188 # 2018
# Filtros para Brasil 2018 Nacional (Rural + Urbano)
INDICADORES_CEPAL: list[int] = [PAISES[0]] + [AÑOS, AREA_GEOGRAFICA] + [indicador for _, _, indicador in INDICADORES_GLOBAL]
CEPALSTAT_PARAMS: dict[str,list|str|int] = {
"members": ",".join(map(str, INDICADORES_CEPAL)),
"lang": "es",
"format": "json",
"in": 1
}
CEPAL_ENDPOINT = f"https://api-cepalstat.cepal.org/cepalstat/api/v1/indicator/{INDICADOR}/data"
# Testeando endpoint en Python
respuesta = requests.get(CEPAL_ENDPOINT, params=CEPALSTAT_PARAMS)
respuesta.encoding = "utf-8"
cepal_data = respuesta.json()
print(pd.Series(cepal_data["body"]["metadata"]))>>>
indicator_id 3390
indicator_name Distribución del ingreso de los hogares, por d...
theme Estadísticas e Indicadores Sociales
area Distribución del ingreso
note
unit Porcentaje
data_features Cálculo proveniente de encuestas de hogares
definition Estimación de la proporción del ingreso total ...
calculation_methodology 1.<b>Cálculo del indicador:</p>\r\n<p> En prim...
comments <p>Estas cifras corresponden a una serie actua...
decimals 1
last_update Dec 24 2024 9:28AM
dtype: objectComo podemos observar, hemos consultado y obtenido datos correctamente del endpoint de CEPALSTAT, mostrando los metadatos del indicador 3390, “Distribución del ingreso de los hogares, por deciles y área”. Entonces, con estos datos obtenidos debemos construir un DataFrame con los deciles que nos permita comenzar a calcular Gini. Con todo esto, ya es momento de implementar la función deciles_cepal() de una forma sencilla que nos permita obtener este dataframe:
def deciles_cepal(endpoint: str, params: dict) -> 'DataFrame':
respuesta = requests.get(endpoint, params=params)
respuesta.encoding = "utf-8"
data = respuesta.json()
#print(json.dumps(data["body"]["data"], indent=2, ensure_ascii=False))
deciles = pd.DataFrame(data["body"]["data"])\
.sort_values(by="dim_920", ascending=True)\
.rename(columns={"value": "tasa_ingreso"})
deciles["tasa_ingreso"] = pd.to_numeric(deciles["tasa_ingreso"], errors="coerce")
deciles["tasa_ingreso"] = (deciles[["tasa_ingreso"]]/100)
# Reciclamos los nombres de INEGI
deciles.index = nombres
return deciles
decilesbr2018 = deciles_cepal(CEPAL_ENDPOINT, CEPALSTAT_PARAMS)
print(decilesbr2018["tasa_ingreso"])>>>
Decil 1 0.015
Decil 2 0.034
Decil 3 0.042
Decil 4 0.057
Decil 5 0.067
Decil 6 0.058
Decil 7 0.089
Decil 8 0.109
Decil 9 0.151
Decil 10 0.379
Name: tasa_ingreso, dtype: float64Para Uruguay:
INDICADORES_CEPAL[0] = PAISES[2]
CEPALSTAT_PARAMS["members"] = ",".join(map(str, INDICADORES_CEPAL))
decilesug2018 = deciles_cepal(CEPAL_ENDPOINT, CEPALSTAT_PARAMS)
print(decilesug2018["tasa_ingreso"])>>>
INDICADORES_CEPAL[0] = PAISES[2]
CEPALSTAT_PARAMS["members"] = ",".join(map(str, INDICADORES_CEPAL))
decilesug2018 = deciles_cepal(CEPAL_ENDPOINT, CEPALSTAT_PARAMS)
print(decilesug2018["tasa_ingreso"])
Decil 1 0.045
Decil 2 0.058
Decil 3 0.067
Decil 4 0.073
Decil 5 0.078
Decil 6 0.090
Decil 7 0.103
Decil 8 0.114
Decil 9 0.144
Decil 10 0.227
Name: tasa_ingreso, dtype: float64Hemos logrado homologar los datos de ambas APIs: CEPAL e INEGI, obteniendo el mismo formato en el dataframe: Una columna con la tasa de ingreso de decil. Ahora podemos proceder a programar la función que hará los cálculos sobre los dos dataframes que hemos trabajado para obtener el índice Gini.
Función de cálculos sobre DataFrame
Con estos datos curados, podemos procesar a calcular Gini. Para ello implementaremos la función gini(), que recibe como parámetro el dataframe curado:
def gini(datos: 'DataFrame') -> 'numpy.float64':
# Cálculo de acumulado de ingreso
datos["acumulado_ingreso"] = datos["tasa_ingreso"].cumsum()
# Cálculo de tasa de población
datos["tasa_poblacion"] = 1/len(datos)
# Cálculo de acumulado de población
datos["acumulado_poblacion"] = datos["tasa_poblacion"].cumsum()
# Cálculo de índice Gini
X = datos["acumulado_poblacion"]
Y = datos["acumulado_ingreso"]
datos["gini_i"] = (X.shift(-1)-X)*(Y.shift(-1)+Y) # Método (1)IndiceGini
datos["gini_i"] = datos["gini_i"].fillna(0)
gini = abs(1-datos["gini_i"].sum())
return round(gini, 4)
ginimexico2018 = gini(decilesmx2018)
print(f"Índice Gini para México 2018: {ginimx2018}")>>> Índice Gini para México 2018: 0.4275ginibrasil2018 = gini(decilesbr2018)
print(f"Índice Gini para Brasil 2018: {ginibrasil2018}")>>> Índice Gini para Brasil 2018: 0.4522giniuruguay2018 = gini(decilesug2018)
print(f"Índice Gini para Uruguay 2018: {giniuruguay2018}")>>> Índice Gini para Uruguay 2018: 0.2632Esta función realiza la operación planteada en  para obtener el cálculo. Analicemos un poco los pasos:
para obtener el cálculo. Analicemos un poco los pasos:
- Se generan los acumulados y tasas de población e ingreso partiendo del ingreso corriente de cada decil
- Se aplica sobre la columna gini_i para cada fila de los datos
- Se retorna el valor Gini redondeado a 4 decimales de tipo numpy.float64
Para observar las nuevas columnas creadas en los datos originales:
print(decilesmx2018)>>>
ingreso_corriente tasa_ingreso acumulado_ingreso tasa_poblacion \
Decil 1 9113.231866 0.018370 0.018370 0.1
Decil 2 16099.590912 0.032452 0.050822 0.1
Decil 3 21428.308607 0.043193 0.094015 0.1
Decil 4 26696.370131 0.053812 0.147827 0.1
Decil 5 32317.818967 0.065143 0.212971 0.1
Decil 6 38956.685714 0.078525 0.291496 0.1
Decil 7 47264.244337 0.095271 0.386767 0.1
Decil 8 58885.387456 0.118696 0.505463 0.1
Decil 9 78591.152122 0.158417 0.663880 0.1
Decil 10 166749.859911 0.336120 1.000000 0.1
acumulado_poblacion gini_i
Decil 1 0.1 0.006919
Decil 2 0.2 0.014484
Decil 3 0.3 0.024184
Decil 4 0.4 0.036080
Decil 5 0.5 0.050447
Decil 6 0.6 0.067826
Decil 7 0.7 0.089223
Decil 8 0.8 0.116934
Decil 9 0.9 0.166388
Decil 10 1.0 0.000000
Hasta este punto hemos logrado calcular el índice Gini correctamente, ya sea con datos de INEGI o CEPAL, además de tener un dataframe con los cálculos realizados. Ahora, podemos pasar a construir el gráfico interactivo de la Curva Lorenz, usando el módulo plotly de Python.
Función de graficación
En este subtítulo crearemos la función grafico() que recibe un parámetro: el Dataframe que hemos procesado anteriormente con la función gini(). Usaremos Graphic Objects de Plotly para crear un gráfico interactivo:
import plotly.graph_objects as go
import pandas as pd
def grafico(datos: list['DataFrame'], nombres: list[str], colores: list[str] = None):
fig = go.Figure()
# Definir colores si no se especifican
if colores is None:
colores = ['#0072CE', '#D62728', '#2CA02C', '#FF7F0E', '#9467BD'] # Azul, Rojo, Verde, Naranja, Morado
# Graficar cada curva de Lorenz
for i, df in enumerate(datos):
fig.add_trace(go.Scatter(
x=df['acumulado_poblacion'],
y=df['acumulado_ingreso'],
mode='lines+markers',
name=f'Distribución Real - {nombres[i]}',
line=dict(color=colores[i % len(colores)], width=3),
marker=dict(size=6)
))
# Línea de igualdad (Distribución Perfecta)
fig.add_trace(go.Scatter(
x=[0, 1],
y=[0, 1],
mode='lines',
name='Distribución Perfecta',
line=dict(color='gray', dash='dash', width=2)
))
# Configuración del diseño
fig.update_layout(
title='Curva de Lorenz',
xaxis=dict(
title='Deciles de la Población (Acumulado)',
tickmode='array',
tickvals=[i/10 for i in range(1, 11)],
ticktext=[str(i) for i in range(1, 11)],
),
yaxis=dict(
title='Proporción del Ingreso (Acumulado)',
range=[0, 1]
),
legend=dict(
orientation='h',
x=0.5,
y=-0.2,
xanchor='center',
yanchor='top'
),
template='plotly_white',
hovermode='x unified'
)
return fig
# Ejemplo de uso sólo con México
lorenz_comparacion = grafico(
[decilesmx2018],
['México 2018']
)
lorenz_comparacion.show()
Así se verá nuestro gráfico interactivo:
Para graficar los tres países:
# Ejemplo de uso con múltiples países
lorenz_comparacion = grafico(
[decilesmx2018, decilesbr2018, decilesug2018],
['México 2018', 'Brasil 2018', 'Uruguay 2018']
)
lorenz_comparacion.show()Listo. Hemos cumplido el objetivo inicial de la publicación. Ahora, pasemos a la sección final, que son los tips de publicación en un sitio web. En este caso, en WordPress.
Tips de publicación
Para publicar el gráfico que obtuvimos en Python con plotly, debemos crearnos una cuenta gratuita en Plotly Chart Studio:
Guardar API Key generada en
un lugar seguro
Recibiremos un email para confirmar el registro. Una vez confirmado, podemos hacer login en Plotly Chart Studio para generar una API Key que necesitaremos más adelante.
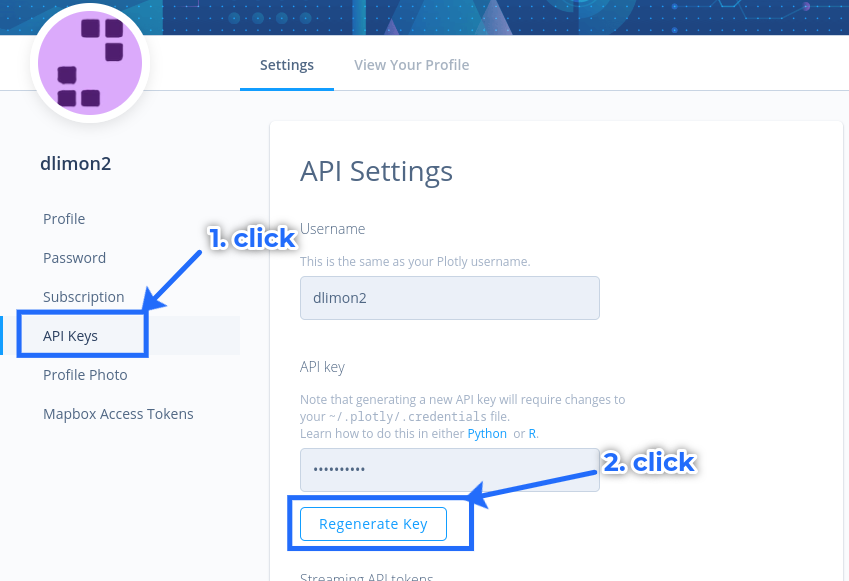
Una vez con la sesión iniciada en Plotly Chart Studio, vamos a los ajustes de perfil y a API Key:

Hacemos click en “Regenerate Key”, ponemos la contraseña y esto nos devolverá una API Key, que debemos almaccenar:
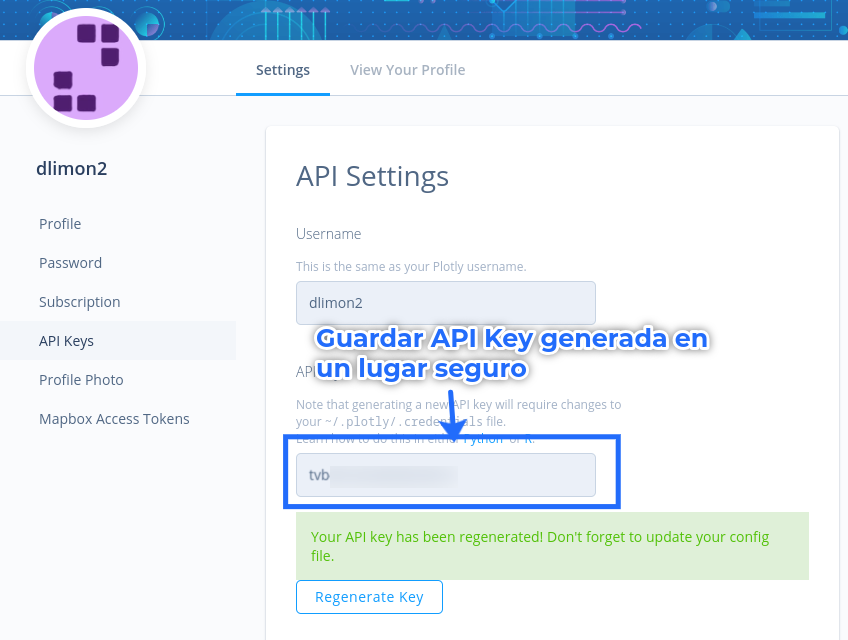
Una vez que tenemos la API Key, podemos regresar a nuestro código.
Ya tenemos el gráfico de la curva de Lorenz almacenado en la variable lorenz_mx_2022, por lo que queremos publicar dicho gráfico. Lo primero que debemos hacer es importar chart_studio y algunas herramientas para hacer la publicación a nuestra cuenta de Plotly. Recuerda cambiar TU_API_KEY por la key obtenida en el paso anterior
import chart_studio
import chart_studio.plotly as py
import plotly.tools as tls
cs_username="dlimon2"
cs_api_key="TU_API_KEY"
chart_studio.tools.set_credentials_file(username=cs_username, api_key=cs_api_key)Ahora, simplemente llamamos py.plot() y le pasamos el gráfico y un par de parámetros más:
py.plot(lorenz_comparacion, filename="Curva Lorenz Brasil, México, Uruguay 2018", auto_open=False)>>> https://plotly.com/~dlimon2/5/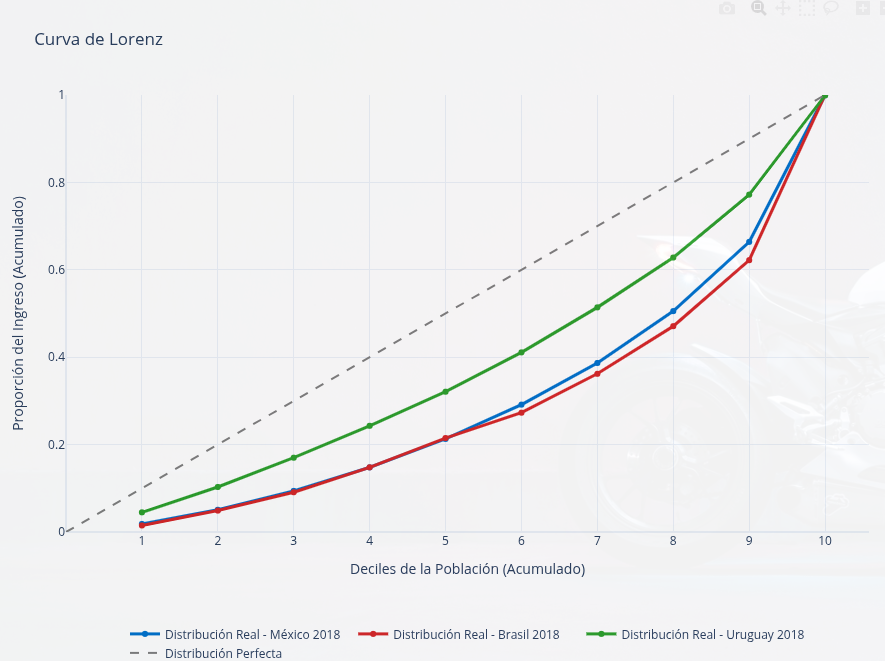
Esto nos devuelve un URL, que si visitamos, veremos el gráfico dentro de Chart Studio:
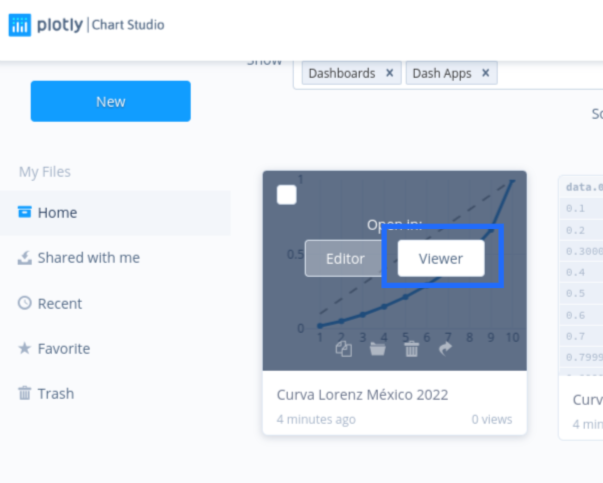
Ahora, ¿cómo publicar este gráfico, que ya está en internet, en un sitio web WordPress?. Primero, debemos ir de vuelta a nuestra cuenta de Chart Studio a la parte de My Files:

Allí veremos el gráfico que acabamos de subir, le damos click a Viewer:
Ahorta, buscamos un botón que dice Embed code y le damos click:
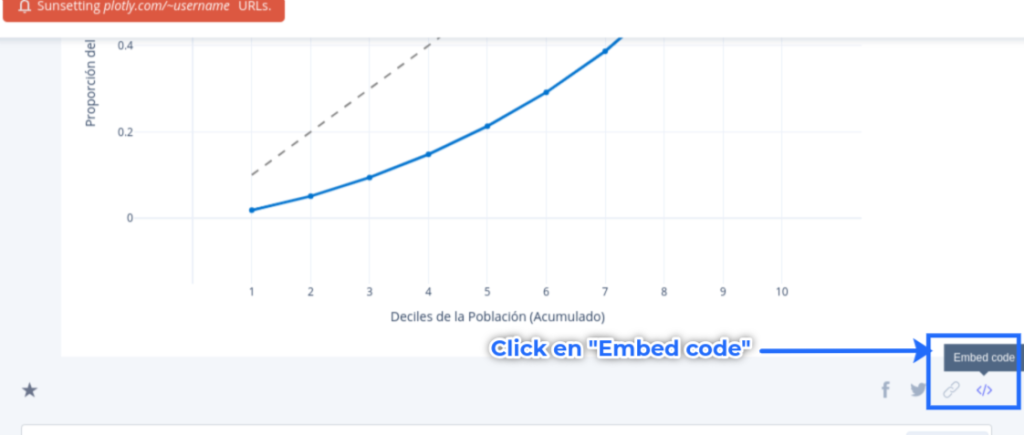
Simplemente copiamos el contenido de iframe, y lo podemos insertar en un bloque de HTML de WordPress al escribir una entrada de blog:
Insertamos este elemento como bloque HTML en un post de WordPress:

🔥Resultado final 🔥
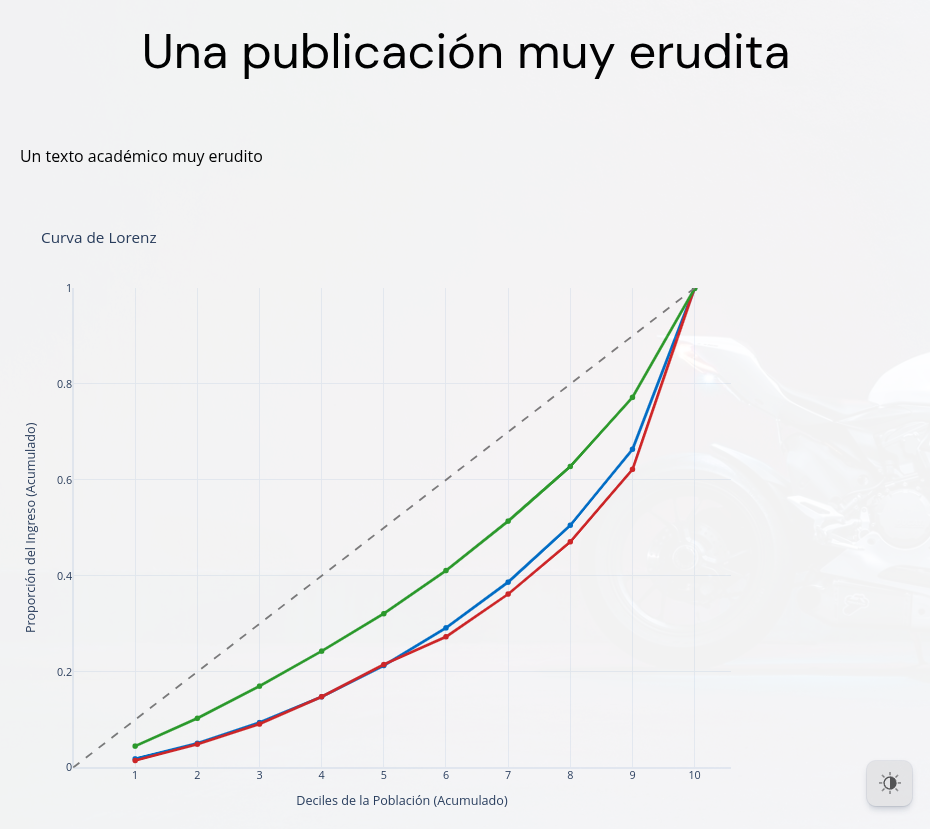
¡Listo! Tenemos una publicación online con gráfico interactivo. Excelente si queremos presentar resultados de diversa índole de una forma atractiva y profesional 😀
Como reflexión final, puedo destacar que hasta este punto hemos logrado el objetivo, pero siempre se puede ir al siguiente nivel. Durante este tutorial hemos desarrollado lógica que esta’toda desperdigada en un notebook interactivo. Tengo en mente hacer una parte dos de esta publicación, donde se trabaje y empaquete este código para hacerlo modular, implementando Programación Orientada a Objetos para abstraer esta lógica en un módulo reutilizable.
Pero hasta ahora, los resultados son satisfactorios. ¡Salud!
~ Daniel Limón